翻译自:https://preshing.com/20130618/atomic-vs-non-atomic-operations/
略有删改
关于Web上原子操作的知识已经很多,通常集中在原子读-修改-写(RMW)操作上。但是,这些并不是原子操作的唯一种类。还有原子加载和存储,它们同样重要。在这篇文章中,我将在处理器级别和C / C ++语言级别比较原子加载和存储与它们的非原子操作。在此过程中,我们将阐明C ++ 11的“数据竞争”概念。
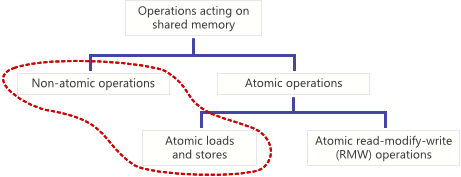
如果共享内存相对于其他线程在单个步骤中完成,则该操作是原子的。在共享变量上执行原子存储时,没有其他线程可以观察到修改是半完成的。对共享变量执行原子加载时,它将读取单个时间点出现的整个值。非原子加载和存储不做那些保证。
没有这些保证,无锁编程将是不可能的,因为您永远无法让不同的线程同时操作共享变量。我们可以将其公式化为:
每当两个线程同时对共享变量执行操作,并且其中一个操作执行写操作时,两个线程都必须使用原子操作。
如果您违反了此规则,并且任一线程使用了非原子操作,那么您将拥有C ++ 11标准所指的数据竞争(不要与Java的数据竞争概念相混淆,或更一般的竞争条件)。C ++ 11标准没有告诉您为什么数据竞争很糟糕。当您仅拥有一个时,才会导致“未定义的行为”(第1.10.21节)。此类数据竞争不佳的真正原因实际上很简单:它们导致读取和写入中断。
内存操作可能是非原子的,因为它使用了多个CPU指令,甚至在使用单个CPU指令时也有可能是非原子的,或许因为您正在编写可移植的代码,而根本无法做出某些操作是原子的假设。让我们看几个例子。
由于多个CPU指令而导致非原子
假设您有一个64位的全局变量,初值为零。
1 | uint64_t sharedValue = 0 ; |
在某个时候,您可以为该变量分配一个64位值。
1 | void storeValue() |
使用GCC为32位x86平台编译此函数时,它将生成以下机器代码。
1 | $ gcc -O2 -S -masm=intel test.c |
如您所见,编译器使用两条单独的机器指令实现了64位分配。第一条指令将低32位设置为0x00000002,第二条指令将高32位设置为0x00000001。显然,此分配操作不是原子的。如果sharedValue被不同线程并发访问,则可能会出错:
- 如果
storeValue在两个机器指令之间抢占了一个线程调用,它将0x0000000000000002保留在内存中 – 损坏的write。在这一点上,如果另一个线程读取sharedValue,它将收到这个完全错误的值。(PS:读错误) - 更糟糕的是,如果在两个指令之间抢占了一个线程,而另一个线程
sharedValue在第一个线程恢复之前进行了修改,则将导致永久性的写入中断:一个线程的高32位,另一个线程的低32位。(PS:写错误) - 在多核设备上,甚至没有必要抢占其中一个线程来进行写入中断。当线程调用时
storeValue,sharedValue在另一半内核上执行的任何线程都可以在只有一半更改可见的时候读取。(PS:此处并不是讨论私有缓存与全局内存不一致问题,因此已经限制在读写共享变量,此时讨论的是两个线程在两个核心上真正同时访问一个数据,数据一半的读写交错)
并发读sharedValue会带来一系列问题:
1 | uint64_t loadValue() |
在这里,编译器也使用两条机器指令来实现装入操作:第一条将低32位读入eax,第二条将高32位读入edx。在这种情况下,如果sharedValue在两个指令之间可以看到并发存储,则即使并发存储是原子的,也会导致读取中断。
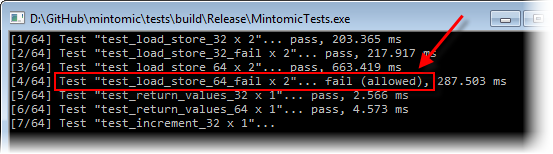
这些问题不仅仅是理论上的。Mintomic的测试套件包括一个称为的测试用例test_load_store_64_fail,其中一个线程使用普通分配运算符将一堆64位值存储到单个变量,而另一个线程从同一变量重复执行普通加载,从而验证每个结果。如预期的那样,在多核x86上,该测试始终失败。
非原子CPU指令
即使通过单个CPU指令执行存储操作,也可以是非原子操作。例如,ARMv7指令集包括该strd指令,该指令将两个32位源寄存器的内容存储到内存中的单个64位值。
1 | strd r0, r1, [r2] |
在某些ARMv7处理器上,该指令不是原子的。当处理器看到此指令时,实际上在后台执行了两个单独的32位存储(第A3.5.3节)。同样,在单独内核上运行的另一个线程可能会观察到写入中断。有趣的是,甚至在单核设备上也可能发生写入中断:实际上,在两个内部的32位存储器
之间
可能会发生系统中断(例如,计划的线程上下文切换)!在这种情况下,当线程从中断中恢复时,它将strd再次重新启动指令。
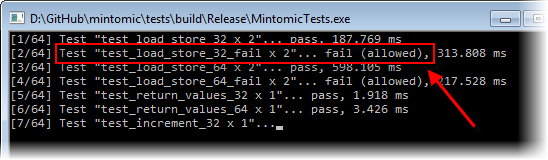
再举一个例子,众所周知,在x86上,mov如果内存操作数是自然对齐的,则32位指令是原子的,否则是非原子的。换句话说,仅当32位整数位于4的精确倍数的地址上时,原子性才得到test_load_store_32_fail保证。如本文所述,该测试始终在x86上成功,但是如果您修改测试以强制sharedInt使用某些未对齐的地址,它将失败。在我的Core
2 Quad Q6600上,sharedInt超过缓存行边界时测试失败:
1 | // 强制sharedInt越过缓存行边界: |
到目前为止,这些信息已经足够了特定于处理器的细节。让我们在C / C ++语言级别上查看原子性。
假定所有C / C ++操作都是非原子的
在C和C ++中,除非编译器或硬件供应商另行指定,否则所有操作都假定为非原子操作-甚至是纯32位整数分配。
1 | uint32_t foo = 0; |
在这种情况下,语言标准没有明确指出是否是原子的。也许整数赋值是原子的,也许不是。由于非原子操作不做任何保证,因此按定义,C语言中的纯整数赋值是非原子的。
实际上,我们通常对目标平台了解更多。例如,众所周知,在所有现代x86,x64,Itanium,SPARC,ARM和PowerPC处理器上,只要目标变量自然对齐,纯32位整数分配就是原子的。您可以通过查阅处理器手册和/或编译器文档来进行验证。在游戏行业中,我可以告诉您,很多32位整数分配都依赖于此特定保证。
但是,在编写真正可移植的C和C ++时,有一个长期的传统,即我们假装除语言标准告诉我们的内容外,一无所知。可移植的C和C ++旨在:在过去、现在和未来的所有可能的计算设备上运行。就个人而言,我想像一台机器,只有先将其混合才能更改内存:

在这样的机器上,您绝对不希望与普通分配同时执行并发读取。您可能最终会读取完全随机的值。
在C ++ 11中,终于有了一种执行真正可移植的原子加载和存储的方法:C ++ 11原子库。使用C ++ 11原子库执行的原子加载和存储甚至可以在上述虚拟计算机上工作-即使这意味着C ++ 11原子库必须秘密锁定互斥体才能使每个操作原子化。还有我上个月发布的Mintomic库,该库不支持那么多平台,但是可以在多个较旧的编译器上运行,经过手动优化,并且保证没有锁。
松的原子操作
让我们回到本文sharedValue前面的原始示例。我们将使用Mintomic对其进行重写,以便在Mintomic支持的每个平台上原子地执行所有操作。首先,我们必须将声明sharedValue为Mintomic的原子数据类型之一。
1 |
|
该mint_atomic64_t类型保证在每个平台上进行原子访问时都可以正确对齐内存。这很重要,因为例如,与Xcode
3.2.5捆绑在一起的用于ARM的GCC
4.2编译器不能保证朴素的uint64_t将以8字节对齐。
在storeValue中,我们必须调用mint_store_64_relaxed,而不是执行简单的非原子赋值。
1 | void storeValue() |
同样,在loadValue中,我们调用mint_load_64_relaxed。
1 | uint64_t loadValue() |
使用C ++
11的术语,这些函数现在无数据竞争。并行执行时,无论代码是在ARMv6 /
ARMv7(Thumb或ARM模式),x86,x64还是PowerPC上运行,读取或写入都绝对不会被破坏。mint_load_64_relaxed以及mint_store_64_relaxed这两个函数都可以扩展为cmpxchg8bx86上的内联指令。对于其他平台,请咨询Mintomic的实现。
这是用C ++ 11编写的完全相同的东西:
1 |
|
您会注意到,由_relaxed各种标识符的后缀证明,Mintomic和C
++
11示例都使用了relaxed原子。该_relaxed后缀是一个提醒:几乎没有关于内存排列顺序的保证。
特别地,由于编译器的重排列或处理器自身的内存重排列,将relaxed原子操作重排列在程序顺序之前或之后仍然是合法的。就像非原子操作一样,编译器甚至可以对冗余的relaxed原子操作执行优化。在所有情况下,该操作仍然是原子的。
当同时操作共享内存时,我认为最好始终使用Mintomic或C ++ 11原子库函数,即使在您知道目标平台上已经是原子加载或存储的情况下,也是如此。原子库函数提醒我们,在其他地方,此变量被并发访问。
希望现在已经更加清楚了,为什么世界上最简单的无锁哈希表使用Mintomic库函数来同时操作来自不同线程的共享内存。
PS:
硬件支持
原子性不可能由软件单独保证–必须需要硬件的支持,因此是和架构相关的。在x86 平台上,CPU提供了在指令执行期间对总线加锁的手段。CPU芯片上有一条引线#HLOCK pin,如果汇编语言的程序中在一条指令前面加上前缀”LOCK”,经过汇编以后的机器代码就使CPU在执行这条指令的时候把#HLOCK pin的电位拉低,持续到这条指令结束时放开,从而把总线锁住,这样同一总线上别的CPU就暂时不能通过总线访问内存了,保证了这条指令在多处理器环境中的原子性。
原子操作大部分使用汇编语言实现,因为C语言(或其它高级语言)并不能实现这样的操作。
意义
在多线程访问共享资源时,能够确保所有其他的线程都不在同一时间内访问相同的资源。原子操作(atomic
operation)是不需要synchronized-with的。

