翻译自:https://preshing.com/20120913/acquire-and-release-semantics/
略有删改
一般而言,在无锁编程中,线程可以通过两种方式操纵共享内存:
- 相互竞争资源
- 将信息从一个线程传递到另一个线程。
获取和释放语义对于后者至关重要:在线程之间可靠地传递信息。实际上,我敢冒险猜测不正确或丢失的获取和释放语义是无锁编程错误的第一类型。
在本文中,我将演示在C
++中实现获取和释放语义的各种方法。我将以介绍性的方式介绍C ++ 11
atomic库标准,因此您无需了解它。从一开始就很清楚,这里的信息适用于没有
顺序一致性的无锁编程。我们直接在多核或多处理器环境中处理内存排序。
不幸的是,术语 acquire and release semantics 似乎比术语
lock-free
更乱,因为您搜索网络的次数越多,您会发现看似矛盾的定义。布鲁斯·道森(Bruce
Dawson)在本白皮书的一半左右位置提供了两个很好的定义(归功于Herb
Sutter)。我想提供一些我自己的定义,以接近C ++ 11
atomic背后的原理:
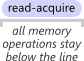
获取语义是仅适用于从共享内存读取的操作的属性,无论它们是读-修改-写操作还是普通加载。然后将该操作视为已读取。获取语义防止在它之后的任何读写操作的内存重新排序到read-acquire的前面。

释放语义是仅适用于写入共享内存的操作的属性,无论它们是读-修改-写操作还是普通存储。然后将该操作视为已写入。释放语义防止在它之前的任何读写操作的内存重新排列到write-release的后面。
一旦理解了上面的定义,就不难发现使用我在上一篇文章中详细描述的内存屏障类型的简单组合就可以实现获取和释放语义。必须(以某种方式)将屏障放置在读获取操作之后,但在写入释放之前。[更新:请注意,在单个内存操作的技术上,这些屏障比获取和释放语义所要求的更为严格,但它们确实达到了预期的效果。]

很棒的是获取或释放语义都不需要使用#StoreLoad屏障,这个屏障通常是更昂贵的内存屏障类型。例如,在PowerPC,所述lwsync(简称“轻量同步”)指令同时扮演#LoadLoad,#LoadStore和#StoreStore三个障碍的角色,比包含#StoreLoad屏障的sync指令更轻量。
显示使用平台相关的屏障
获得期望的内存屏障的一种方法是发出明确的屏障指令。让我们从一个简单的例子开始。假设我们正在为PowerPC进行编码,并且__lwsync()是发出lwsync指令的编译器固有函数。由于lwsync提供了许多屏障类型,因此我们可以在以下代码中使用它来根据需要建立获取或释放语义。在线程1中,存储Ready变为写释放,而在线程2中,来自的负载Ready变为读取获取。

如果我们让两个线程都运行,并找到r1 == 1,则可以确认在线程1中赋给A的值已成功传递给线程2。因此,我们可以保证r2 == 42。在我以前的帖子,我已经给了一个漫长的比喻为说明#LoadLoad和#StoreStore如何工作的,所以我不会在这里老调重弹这个解释。
用正式的术语来说,我们说Ready 的存储与
加载同步。另外,我在此处单独写了一篇关于synchronizes-with
的文章
。到目前为止,足以说这种技术正常工作,获取和释放语义必须应用于同一变量。在这个例子中,Ready和存储和加载必须都是原子操作。这里Ready与int简单对齐
,操作在PowerPC上已经是原子的。
在可移植C ++ 11中使用屏障
上面的示例是特定于编译器和处理器的。支持多种平台的一种方法是将代码转换为C
++ 11。所有C ++
11标识符都存在于std名称空间中,因此,为了使下面的示例简短,让我们假设该语句using namespace std;位于代码的较早位置。
C ++
11的原子库标准定义了一个可移植函数atomic_thread_fence(),该函数采用单个参数来指定屏障的类型。该参数有几个可能的值,但是我们在这里最感兴趣的值是memory_order_acquire和memory_order_release。我们将使用此功能代替__lwsync()。
在此示例完成之前,还需要进行其他更改。在PowerPC上,我们知道这两个操作Ready都是原子的,但是我们不能对每个平台都做此假设。为了确保所有平台上的原子性,我们将把Ready的类型从int更改为atomic。我知道,如果考虑对齐的int的加载和存储在当今存在的每个现代CPU上都是原子的,这是一个愚蠢的改变。我将在synchronize-with的帖子中写更多有关此的内容,但是现在,让我们为理论上100%正确的热情做此事。无需更改A。

上面的memory_order_relaxed意味着“确保这些操作是原子的,但不要强加尚不存在的任何排序约束/内存障碍。”
再一次,上述两个atomic_thread_fence()调用在PowerPC上都可以使用lwsync实现。同样,在ARM上它们都可以使用dmb指令实现,我认为它至少与PowerPC的lwsync一样有效。在x86/64上,两个atomic_thread_fence()调用都可以简单地实现为编译器障碍,因为通常x86/64上的每个加载都已经隐含了获取语义,每个存储都隐含了释放语义。这就是为什么x86/64通常被认为是有序的原因。
在可移植C ++ 11中不直接使用屏障
在C ++
11中,Ready无需发出显式的屏障指令就可以实现获取和释放语义。您只需要在以下操作上直接指定内存排序约束Ready:

可以将其视为将每个屏障指令滚动到Ready自己的操作中。[更新:请注意,此表格与使用独立屏障的版本不完全相同;从技术上讲,它不太严格。]编译器将发出任何必需的指令,以获得所需的屏障效果。特别是在Itanium上,每个操作都可以轻松实现为一条指令:ld.acq和st.rel。与以前一样,r1 == 1表示一个synchronizes-with关系,确认r2 == 42是对的。
实际上,这是在C ++
11中表达获取和释放语义的首选方法。实际上,atomic_thread_fence()在上一示例中使用的功能是在标准创建的后期才添加的。
使用锁实现获取释放语义
如您所见,本文中的所有示例均未利用获取和释放语义所提供的#LoadStore屏障。确实,只需要#LoadLoad和#StoreStore。这仅仅是因为在本文中,我选择了一个简单的示例让我们专注于API和语法。
#LoadStore变得很重要的一种情况是,使用获取和释放语义来实现(互斥)锁。实际上,这就是获取与释放语义名称的来源:获取锁意味着获取语义,而释放锁则意味着释放语义!介于两者之间的所有内存操作都包含在一个漂亮的小屏障夹中,以防止任何不希望的内存跨越边界重新排序。

在这里,获取和释放语义可确保在持有锁的同时进行的所有修改将完全传播到获取锁的下一个线程。锁的每种实现,即使您自己的实现,也应提供这些保证。同样,这都是为在线程之间可靠地传递信息,尤其是在多核或多处理器环境中。
PS:不论何种方式实现获取和释放语义,底层都是借助处理器或编译器的内存屏障指令来完成。语言层次提供的获取释放语义只是对底层指令的封装。

