翻译自:https://preshing.com/20130922/acquire-and-release-fences/
我认为,获取(acquire fence, afence)和释放屏障(release fence, rfence)目前在网络上还是被误解了。太糟糕了,因为C ++ 11标准委员会在指明这些内存保屏障的含义方面做得很好。它们提供了强大的算法,可以在多个内核之间很好地扩展,并且可以很好地映射到当今最常见的CPU架构上。
首先,第一件事:获取和释放屏障被认为是低级别的无锁操作。如果您坚持使用更高级别的,顺序一致的原子类型(例如volatileJava
5+中的变量或C ++
11中的默认原子),则不需要获取和释放屏障。折衷是顺序一致类型对于某些算法来说可扩展性或性能稍差。
另一方面,如果您是在C ++
11发布前为多核设备开发的,则您可能会对获取和释放屏障感兴趣。也许像我一样,您还记得lwsync在Xbox
360上同步线程时在一些内部函数的放置上遇到了麻烦。最酷的是,一旦您了解了获取和释放屏障,您实际上就会看到我们一直在尝试使用这些特定于平台的屏障来完成的工作。
您可能会想到,获取和释放屏障是独立的内存屏障,这意味着它们没有与任何特定的内存操作耦合。那么,它们如何工作?
一个afence,防止在其之前的任何读操作内存重排序到其之后的任何读写操作中。
An acquire fence prevents the memory reordering of any read which precedes it in program order with any read or write which follows it in program order.
一个rfence,防止在其之后的任何读写操作内存重排序到其之前的任何写操作中。
A release fence prevents the memory reordering of any read or write which precedes it in program order with any write which follows it in program order.
换句话说,就此处说明的屏障类型而言,获取屏障用作#LoadLoad+
#LoadStore屏障,而释放屏障用作#LoadStore+
#StoreStore屏障。他们声称要做的就是这些。

使用C ++ 11进行编程时,可以使用以下函数调用它们:
1 |
|
在C11中,他们采用以下形式:
1 |
|
并使用Mintomic(一个小型的、可移植的无锁API):
1 |
|
在SPARC-V9架构上,可以使用membar #LoadLoad | #LoadStore指令实现获取隔离,而发布隔离可以实现为membar #LoadStore | #StoreStore。在其他CPU体系结构上,实现上述库的人员必须将这些操作转换为次要的事情-某些CPU指令至少提供所需的屏障类型,甚至可能更多。在PowerPC上,第二件事是lwsync。在ARMv7上,第二件事是dmb。在Itanium上,第二好是mf。在x86
/ 64上,根本不需要CPU指令。如您所料,获取和释放围墙也会在编译时限制相邻操作的重新排序。
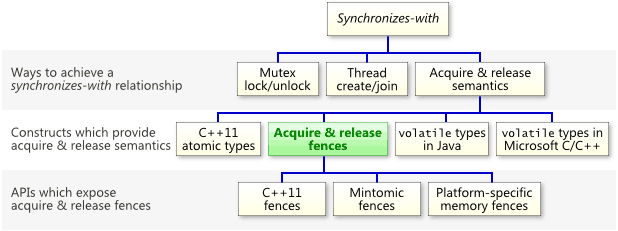
他们可以建立同步关系
有关获取和释放屏障的最重要信息是,它们可以建立同步关系,这意味着它们以允许您在线程之间可靠地传递信息的方式禁止内存重新排序。请记住,如下图所示,获取和释放屏障只是可以建立同步关系的众多构造之一。
正如我之前所展示的,紧随afence后的一个relaxed
加载原子操作将把加载转成read-acquire。类似地,紧随rfence之前的relaxed
存储原子操作将把该存储转换为write-release。例如,如果g_guard具有type
std::atomic,则此行
1 | g_guard.store(1, std::memory_order_release); |
可以安全地替换为以下内容。
1 | std::atomic_thread_fence(std::memory_order_release); |
一种精度:在后一种形式中,存储不再与任何东西同步。它是栅栏本身。要了解我的意思,让我们来看一个详细的示例。
使用获取和释放屏障的演练
我们将以我以前的帖子中的示例为例,并对其进行修改以使用C
++
11的独立获取和发布屏障。这是SendTestMessage函数。现在原子写入是relaxed,并且释放栅栏已紧接其放置。
1 | void SendTestMessage(void* param) |
这是TryReceiveMessage函数。原子读取是relaxed,并且获取栅栏已稍稍置于其后。在这种情况下,在读取后不会立即出现屏障。我们首先检查是否为ready != 0,因为这是真正需要屏障的唯一情况。
1 | bool TryReceiveMessage(Message& result) |
现在,如果TryReceiveMessage碰巧看到SendTestMessage在g_guard上执行了写操作,那么它将发出获取屏障,并且同步关系已完成。同样,严格来说,是屏障彼此同步。
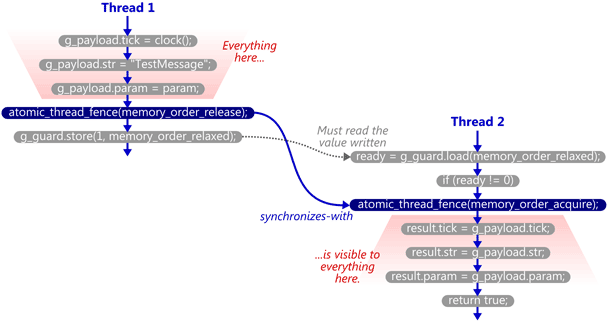
让我们备份一会儿,并根据我前一段时间进行的源代码控制类比考虑此示例。想象一下共享内存是一个中央存储库,每个线程都有该存储库的专用副本。当每个线程操纵其私有副本时,修改会在不可预知的时间不断地“往返”中央存储库。获取和释放屏障用于在这些泄漏之间强制排序。
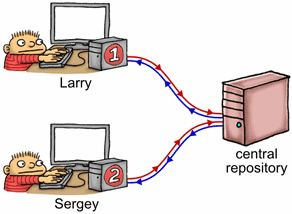
如果我们将线程1想象为名为拉里的程序员,并将线程2想象为名为谢尔盖的程序员,则会发生以下情况:
- 拉里对他的私人副本执行了许多非原子存储
g_payload。 - 拉里发行了释放栅栏。这意味着他之前所有的内存操作(无论何时发生)都将提交到存储库中,然后再执行下一个存储。PS:git push
- 拉里将
1放入了自己的g_guard私有副本中。 - 此后的某个随机时刻,拉里的
g_guard副本push到中央存储库,完全由g_guard自己决定何时push自己。请记住,一旦发生这种情况,我们就可以保证Larry对的更改g_payload也位于中央存储库中。PS:虽然可能不是很及时,但我们一定很自信g_payload的修改一定发生完成了。 - 此后的某个随机时刻,更新的
g_guard从中央存储库leak到谢尔盖的私有副本中,何时leak,完全由g_guard决定。 - 谢尔盖检查他的私人副本
g_guard并看到1。 - 看到这一点,谢尔盖发出了获取围栏。谢尔盖的私人副本的所有内容至少与以前的加载一样新。这样就完成了同步关系。
- 谢尔盖从他的
g_payload私有副本中执行了一堆非原子加载。在这一点上,他可以保证看到拉里编写的值。
请注意,guard变量必须自己从拉里的私有工作区“泄漏”到谢尔盖。当您考虑时,获取和释放防屏障只是在此类泄漏之上附带其他数据的一种方法。
C ++ 11标准得到了支持
C ++ 11标准明确声明此示例将在库和语言的任何兼容实现品上工作。在工作草案N3337 的第29.8.2节中做出了承诺:
如果存在对某个原子对象M进行操作的原子操作X和Y,则释放屏障A 与获取屏障B 同步,这样A排序在X之前,X修改M,Y排序在B之前,并且Y读取由X写入的值或由假设的释放序列X中的任何副作用写入的值都会出现,如果它是一个release操作。
A release fence A synchronizes with an acquire fence B if there exist atomic operations X and Y, both operating on some atomic object M, such that A is sequenced before X, X modifies M, Y is sequenced before B, and Y reads the value written by X or a value written by any side effect in the hypothetical release sequence X would head if it were a release operation.
有很多字母。让我们分解一下。在上面的示例中:
- 释放防屏障A是出现在
SendTestMessage中的释放屏障。 - 原子操作X是执行在
SendTestMessage中的relaxed存储原子操作。 - 原子对象M是保护变量
g_guard。 - 原子操作Y是执行在
TryReceiveMessage中的relaxed加载原子操作。 - 获取栅栏B是出现在
TryReceiveMessage中的获取屏障。
最后,如果relaxed原子加载读取了relaxed原子存储写入的值,则C ++ 11标准将指出,正如我所展示的,屏障彼此同步。
我喜欢C ++
11的可移植的内存屏障方法。过去,其他人曾尝试设计可移植的内存屏障API,但就我个人而言,就独立的屏障而言,很少有人碰到像C
++
11这样的无锁编程的甜蜜。尽管获取和发布屏障可能无法直接转换为本机CPU指令,但它们足够接近,您仍然可以从绝大多数多核设备中获得当前可能的最高性能。这就是为什么我在今年早些时候发布的Mintomic(一个开放源代码库)提供获取和发布屏障以及消耗和完整内存隔离区作为其唯一的内存顺序操作的原因。这是本文中使用Mintomic重写的示例。
在即将发布的帖子中,我将重点介绍一些当前漂浮在网络上的有关获取和发布屏障的误解,并讨论一些性能问题。我还将进一步讨论它们与read-acquire
和write-release的关系,包括这种关系的一些后果,这些后果往往会使人们绊倒。

