翻译自:https://preshing.com/20150402/you-can-do-any-kind-of-atomic-read-modify-write-operation/
略有删改
原子读取-修改-写入操作(或称为“ RMW”)比原子加载和存储更为复杂。它们使您可以从共享内存中的变量读取数据,并同时在该变量中写入一个不同的值。在C ++ 11原子库中,以下所有功能均执行RMW:
1 | std::atomic<>::fetch_add() |
fetch_add例如,从一个共享变量中读取,为其添加另一个值,然后将结果写回–所有这些都是一个不可分割的步骤。您可以使用互斥锁完成相同的操作,但是基于互斥锁的版本并不是无锁的。另一方面,RMW操作被设计为无锁。他们将尽可能利用无锁CPU指令,例如ARMv7上的ldrex/
strex。
新手程序员可能会看上面的函数列表,然后问:“为什么C ++
11提供的RMW操作这么少?为什么会有原子的fetch_add,但没有原子的fetch_multiply,没有fetch_divide又没有fetch_shift_left?”
有两个原因:
- 因为在实践中几乎不需要这些RMW操作。尽量不要对RMW的使用方式有错误的印象。您不能通过采用单线程算法并将每个步骤转换为RMW来编写安全的多线程代码。
- 因为如果确实需要这些操作,则可以自己轻松实现它们。如标题所示,您可以进行任何类型的RMW操作!
比较交换:所有RMW的母亲
在C ++
11中所有可用的RMW操作中,唯一必不可少的是compare_exchange_weak。其他每个RMW操作都可以使用该操作来实现。至少需要两个参数:
1 | shared.compare_exchange_weak(T& expected, T desired, ...); |
该函数尝试将desired值存储到shared,但仅当当前值shared匹配时才存储expected。true返回成功。如果失败,则将shared的当前值加载回expected中,尽管其名称为in/out参数。这称为比较交换操作,所有这些操作都在一个原子的不可分割的步骤中发生。

因此,假设您确实需要原子fetch_multiply操作,尽管我无法想象为什么。这是实现它的一种方法:
1 | uint32_t fetch_multiply(std::atomic<uint32_t>& shared, uint32_t multiplier) |
这称为比较交换循环或CAS循环。该函数反复尝试oldValue与之交换oldValue * multiplier直到成功。如果在其他线程中未发生并发修改,compare_exchange_weak则通常会在第一次尝试时成功。另一方面,如果shared同时被另一个线程修改,则它的值完全有可能在对load调用和compare_exchange_weak调用之间改变,从而导致比较和交换操作失败。在这种情况下,oldValue将使用的最新值进行更新shared,然后循环将重试。
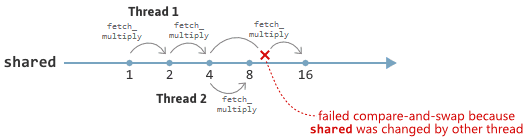
上述实现的fetch_multiply是原子操作也是无锁的。即使CAS循环可能需要不确定的尝试次数,它也是原子的,因为当循环最终修改shared时,它会自动进行。它是无锁的,因为如果CAS循环的单个迭代失败,通常是因为其他线程shared成功修改了。最后一条陈述基于这样的假设,即compare_exchange_weak实际上可以编译为无锁机器代码,更多内容将在下面进行。它还忽略了在某些平台上compare_exchange_weak可能会虚假失败的事实,但这是罕见的事件。
您可以将多个步骤组合成一个RMW
fetch_multiply只需将的值替换为shared相同值的倍数即可。如果我们想执行更复杂的RMW怎么办?我们还可以使操作原子化和无锁吗?我们当然可以。为此提供一个令人费解的示例,下面的函数加载一个共享变量,如果为奇数,则将值减小;如果为偶数,则将其除以一半;仅在大于或等于10的情况下,才将结果存储回去。所有这一切都在单个原子的、无锁操作中:
1 | uint32_t atomicDecrementOrHalveWithLimit(std::atomic<uint32_t>& shared) |
这与以前的想法相同:如果compare_exchange_weak失败(通常是由于另一个线程执行的修改而导致的失败)oldValue被更新了最新的值,然后循环再次尝试。如果在任何尝试中发现newValue小于10,则CAS循环会提前终止,从而有效地将RMW操作变为无操作。
关键是您可以将任何内容放入CAS循环中。将CAS循环的主体视为关键部分。通常,我们使用互斥锁来保护关键部分。通过CAS循环,我们只需重试整个事务,直到成功为止。
这显然是一个综合的例子。AutoResetEvent在我较早的帖子中有关信号量的课程中可以看到一个更实际的示例。它使用具有多个步骤的CAS循环以原子方式将共享变量增加到最大限制1。
您可以将多个变量组合到一个RMW中
到目前为止,我们仅研究了对单个共享变量执行原子操作的示例。如果我们想对多个变量执行原子操作怎么办?通常,我们会使用互斥锁来保护这些变量:
1 | std::mutex mutex; |
这种基于互斥锁的方法是原子的,但显然不是无锁的。这可能已经足够好了,但是为了说明起见,让我们继续将其转换为CAS循环,就像其他示例一样。std::atomic<>是一个模板,因此我们实际上可以将两个共享变量都打包到一个struct中,并像以前一样应用相同的模式:
1 | struct Terms |
此操作是否无锁?现在,我们正在冒险进入骰子领域。正如我在开始时所写的那样,C
++
11原子操作的设计“尽可能”利用了无锁CPU指令,这是一个宽松的定义。在这种情况下,我们包装std::atomic<>了一个结构Terms。让我们看看GCC
4.9.2如何为x64编译它:

我们很幸运。编译器非常聪明,它可以看到Terms适合单个64位寄存器,并lock cmpxchg使用来实现compare_exchange_weak。编译后的代码是无锁的。
这就提出了一个有趣的观点:通常,C ++
11标准不能保证原子操作是无锁的。实在有太多的CPU体系结构无法支持,并且有太多的方法来专门化std::atomic<>模板。您需要检查编译器以确保绝对正确。但是,实际上,当满足以下所有条件时,可以假定原子操作是无锁的,这是非常安全的:
- 编译器是MSVC,GCC或Clang的最新版本。
- 目标处理器是x86,x64或ARMv7(可能还有其他处理器)。
- 的原子类型是
std::atomic,std::atomic或std::atomic对于一些类型T。
作为个人喜好,我喜欢在第三点上挂上帽子,并限制自己使用显式整数或指针类型的特化std::atomic<>模板。我在上一篇文章中描述的安全位域技术为我们提供了一种使用显式整数特化std::atomic来重写上述函数的便捷方法:
1 | BEGIN_BITFIELD_TYPE(Terms, uint64_t) |
我们将几个值打包到原子位域中的一些实际示例包括:
通常,只要您有少量数据受互斥锁保护,并且可以将数据完全打包为32位或64位整数类型,则始终可以将基于互斥锁的操作转换为无锁RMW操作,无论这些操作实际上是做什么的!这就是我在《信号量惊人的通用》一文中采用的原理,以实现一堆轻量级的同步原语。
当然,这种技术并不是C ++ 11原子库所独有的。我仅使用C ++ 11原子,因为它们现在已经广泛使用,并且对编译器的支持非常好。您可以使用公开比较交换函数的任何库来实现自定义RMW操作,例如Win32,Mach内核API,Linux内核API,GCC原子内置函数或Mintomic。为了简洁起见,在这篇文章中我没有讨论内存排序问题,但是考虑您的原子库所做的保证至关重要。特别是,如果您的自定义RMW操作旨在在线程之间传递非原子信息,那么至少应确保与与某处同步关系。

