PPO(Proximal Policy Optimization): 近端策略优化 PG: Policy Gradient
推导过程

PPO 是在 PG 基础上增加了对 rt 的裁剪,限制策略更新幅度,遵循 “保守更新” 原则。
标准PPO的问题
- At
< 0, 原始rt(θ) >
1+ϵ时,rt(θ)At <
(1+ϵ)At,
此时min操作会选择更小的原始乘积rt(θ)At,裁剪完全不起作用
- 例子:At =
−10,离策略下rt(θ) =
100(极易出现的极端值):
- 原始乘积:100×(−10)=−1000
- 裁剪后乘积:1.2×(−10)=−12
- min (-1000, -12) = -1000,裁剪完全失效,损失项直接取极端负值
- 例子:At =
−10,离策略下rt(θ) =
100(极易出现的极端值):
- 无界性:离策略场景下,rt(θ)可以无限大(当前策略对该动作的概率远高于历史采样策略),At也可以出现极端负值,因此rt(θ)At可以无限趋近于负无穷,完全没有任何下界约束
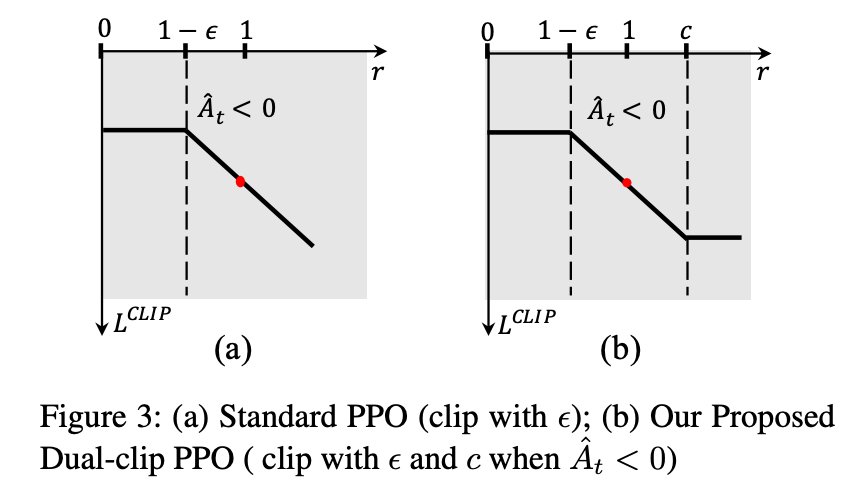
Dual-Clip PPO
Dual-Clip PPO没有修改概率比的裁剪逻辑,而是直接对损失项的最终结果增加了硬下界约束,从根源上解决无界问题:
LDUAL − CLIP(θ) = Et[max(min(rt(θ)At, clip(rt(θ),1−ϵ,1+ϵ)At), c⋅A^t)]
其中c>1是超参数(原论文设为3),当At<0时,c⋅At就是损失项的硬下界 —— 无论rt(θ)多大、At多负,损失项都不会小于c⋅At,彻底解决了标准 PPO 在离策略场景下的无界方差和收敛性问题。
Dual-Clip PPO算法的策略梯度损失计算逻辑: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70def compute_policy_loss(
old_log_prob,
log_prob,
advantages,
response_mask,
cliprange=None,
cliprange_low=None,
cliprange_high=None,
clip_ratio_c=3.0,
loss_agg_mode="token-mean",
):
"""Adapted from https://github.com/huggingface/trl/blob/main/trl/trainer/ppo_trainer.py#L1122
Args:
old_log_prob: `(torch.Tensor)`
shape: (bs, response_length)
log_prob: `(torch.Tensor)`
shape: (bs, response_length)
advantages: `(torch.Tensor)`
shape: (bs, response_length)
response_mask: `(torch.Tensor)`
shape: (bs, response_length)
cliprange: (float)
The clip range used in PPO. See https://arxiv.org/abs/1707.06347
cliprange_low: (float)
The lower clip range used in PPO.
cliprange_high: (float)
The higher clip range used in PPO.
clip_ratio_c: (float) default: 3.0
The lower bound of the ratio for dual-clip PPO, See https://arxiv.org/pdf/1912.09729
loss_agg_mode: (str) choices: "token-mean" /
"seq-mean-token-sum" /
"seq-mean-token-mean" /
"seq-mean-token-sum-norm" /
"token-mean" is the default behavior
Returns:
pg_loss: `a scalar torch.Tensor`
policy gradient loss computed via PPO
pg_clipfrac: (float)
the fraction of policy gradient loss being clipped
ppo_kl: (float)
the estimated KL divergence between the latest updating policy and the old sampling policy
pg_clipfrac_lower: (float)
the fraction of policy gradient loss being clipped when the advantage is negative
"""
assert clip_ratio_c > 1.0, "The lower bound of the clip_ratio_c for dual-clip PPO should be greater than 1.0," + f" but get the value: {clip_ratio_c}."
negative_approx_kl = log_prob - old_log_prob
max_negative_approx_kl = torch.max(negative_approx_kl).cpu().item()
negative_approx_kl_clipped = torch.clamp(negative_approx_kl, min=-10.0, max=10.0)
ratio = torch.exp(negative_approx_kl_clipped)
ppo_kl = verl_F.masked_mean(-negative_approx_kl_clipped, response_mask)
pg_losses1 = -advantages * ratio
if cliprange_low is None:
cliprange_low = cliprange
if cliprange_high is None:
cliprange_high = cliprange
pg_losses2 = -advantages * torch.clamp(ratio, 1 - cliprange_low, 1 + cliprange_high)
clip_pg_losses1 = torch.maximum(pg_losses1, pg_losses2)
pg_clipfrac = verl_F.masked_mean(torch.gt(pg_losses2, pg_losses1).float(), response_mask)
pg_losses3 = -advantages * clip_ratio_c
clip_pg_losses2 = torch.min(pg_losses3, clip_pg_losses1)
pg_clipfrac_lower = verl_F.masked_mean(torch.gt(clip_pg_losses1, pg_losses3) * (advantages < 0).float(), response_mask)
pg_losses = torch.where(advantages < 0, clip_pg_losses2, clip_pg_losses1)
pg_loss = agg_loss(loss_mat=pg_losses, loss_mask=response_mask, loss_agg_mode=loss_agg_mode)
return pg_loss, pg_clipfrac, ppo_kl, pg_clipfrac_lower

