以VeOmni训练框架为例,介绍Qwen3-MoE-30B-A3B模型并行训练方法,参考代码仓库中文档。
Qwen3-MoE-30B-A3B模型
该模型核心参数为:128 个专家、隐藏层维度 2048、中间层维度 768,其 MoE 核心的专家权重张量形状固定为: - 门控投影(Gate projection):[128, 768, 768] - 上投影(Up projection):[128, 768, 2048] - 下投影(Down projection):[128, 2048, 768]
VeOmni分片维度设计
为了兼顾并行灵活性与训练效率,VeOmni 对 EP 和 FSDP2 做了维度解耦设计,这是整个并行方案的核心:
- 专家并行(EP):固定沿张量的dim-0(专家数量维度) 分片,将不同的专家拆分到不同的 EP 并行组中,实现专家级的分布式部署。
- FSDP2 全分片数据并行:针对专家模块,沿张量的dim-1 维度分片(而非 FSDP2 默认的 dim-0);非专家模块仍沿默认维度做全局 FSDP2 分片。
该设计的核心优势是打破了「EP 并行度 × FSDP2 并行度必须严格等于专家总数」的强约束,支持更灵活的并行度配置。
完整并行流程
以 2 台 8-GPU 实例(总计 16 张 GPU,全局 world size=16)、配置EP size=8、FSDP2 size=16的典型场景为例,以下投影层为例,完整并行分片流程如下:
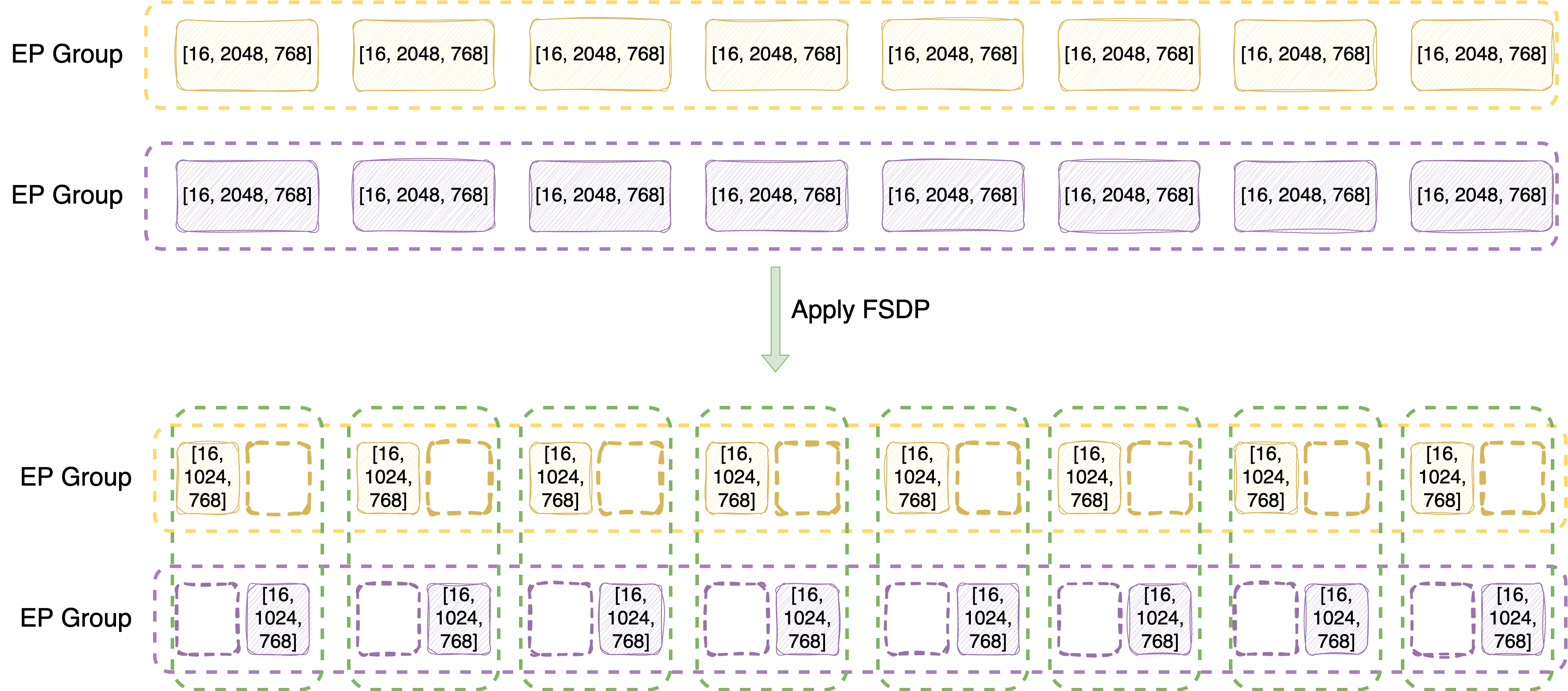
- 第一步:EP 维度分片(专家拆分)
- 单台 8 卡实例组成一个 EP 并行组,第一台实例的 EP 设备网格为[0,1,2,3,4,5,6,7],第二台为[8,9,10,11,12,13,14,15]。
- 沿 dim-0 将 128 个专家均分到 8 个 EP rank 中,每个 rank 分到128/8=16个专家,分片后单 rank 的权重张量变为[16, 2048, 768]。
- 两台实例中,同序号的 rank(如 rank0 与 rank8)持有完全相同的 16 个专家分片,为后续 FSDP2 分片提供基础。
- 第二步:FSDP2 维度分片(权重参数拆分)
- 持有相同专家分片的跨实例 rank,组成独立的 FSDP2 并行组,本示例中每组包含 2 个 rank(如[0,8]),单组 FSDP2 并行度为 2。
- 沿 dim-1 对专家权重做二次分片,每个 rank 的张量进一步切分为[16, 2048/2=1024, 768],完成专家模块的最终分片。
专家/非专家模块的并行规则差异
- 专家模块
- 并行约束:EP size × FSDP2 size = 全局world size(总GPU数)
- 设备网格:逻辑上为[EP, EP_FSDP]的二维设备网格,先做 EP 分片,再对同专家分片的 rank 组做 FSDP2 分片。
- 非专家模块
- 不受 EP 并行影响,仅执行全局 FSDP2 分片,FSDP2 并行度 = 全局 world size。 设备网格:仅[FSDP]的一维设备网格,与常规 FSDP2 全分片训练逻辑一致。
为什么这么设计
MoE 训练有两类完全不同的核心通信,二者对效率的影响不在一个量级:
EP 相关通信:token 路由的AlltoAll,前向把 token 分发到对应专家的 GPU,反向回传梯度。通信量级和 batch size、序列长度正相关,是全连接集体通信,对网络延迟/带宽极度敏感,且很难和计算重叠,是 MoE 训练的头号瓶颈。
FSDP 相关通信:参数的AllGather/ReduceScatter,前向拉取参数分片,反向聚合梯度。通信量级仅和参数量相关,可通过预取完全隐藏在计算中,对延迟敏感度极低。
我们知道不同机器节点之间的通信耗时是比较长的,而节点内通过NVLink通信耗时很短,两者相差1个数据级。因此我们将EP的并行完全限制在节点内,EP AlltoAll 仅在单节点8卡之间走低延迟高带宽的 NVLink,完全无跨节点的 AlltoAll 开销。让 FSDP 的并行跨节点,跨节点仅存在 FSDP2 的极小流量参数通信,且通过定制化预取完全隐藏在计算中,无任何空闲气泡。
VeOmni并行实现细节
Expert Parallelism Details(专家并行细节)
核心实现文件 专家并行(EP)的核心实现逻辑位于 veomni/distributed/parallel_plan.py 文件中。
核心设计思路 VeOmni 作为模型中心化的框架,通过注册模型定义中专家权重的「全限定名(Fully Qualified Name,FQN)」作为属性,来实现专家并行的分片逻辑(以 Qwen3-MoE 为例,可参考 veomni/models/transformers/qwen3_moe/parallel_plan.py)。
具体实现逻辑
- 并行计划(ParallelPlan)定义每个模型会暴露 get_parallel_plan()
方法,该方法返回一个 ParallelPlan 对象,其中包含 ep_plan 字典:
- 键:用于识别专家权重的参数 FQN 匹配模式(如专家层权重的命名模式);
- 值:Shard(dim=…) 对象,固定指定 dim=0(即对「专家数量维度」进行 EP 分片)。
- EP 分片执行与设备网格信息处理对注册的专家模块完成 EP
分片后,框架会立即丢弃设备网格(DeviceMesh)信息,并将参数替换为本地分片的张量。这么做的核心原因:
- 避免在专家计算阶段像 FSDP 那样将分布式参数聚合(gather)回来;
- 基于融合的 MoE 实现,手动控制不同 EP rank 之间的交互逻辑;
- 规避使用 TorchTitan 等实验性 API(如覆盖面向张量并行(TP)的 parallelize_module 方法)来实现 EP,降低实现复杂度。
关键特性 该实现对终端用户完全透明,无需额外配置,框架会自动完成专家权重的 EP 分片、本地张量替换及 rank 间交互控制。
FSDP2 Details(FSDP2 实现细节)
FSDP2 适配的核心实现位于 veomni/distributed/torch_parallelize.py,是 VeOmni 实现 EP+FSDP2 混合并行的核心模块,针对 MoE 模型的专家 / 非专家模块做了深度定制化适配,解决原生 FSDP2 与专家并行的兼容问题,同时最大化通信与计算的重叠效率。
1. 自底向上的分片策略(Sharding from the bottom up)
FSDP2 的核心能力依赖 fully_shard 接口,该接口要求必须以 自底向上(可以理解成自内向外) 的层级顺序执行分片。针对 EP+FSDP2 的嵌套混合并行场景,VeOmni 设计了分层分片的执行流程,简化逻辑如下:
1 | # 简化的核心执行逻辑 |
该分层逻辑保证了专家模块的分片优先级,避免与非专家模块的分片逻辑冲突,同时兼容 EP 已完成的分片结果。
2. 分模块的正确维度分片(Sharding Modules with Correct Dimensions)
针对专家模块与非专家模块,VeOmni 设计了差异化的分片策略,核心设计如下:
分片维度解耦:专家模块的 EP 并行固定沿 dim-0(专家数量维度)分片,而专家模块的 FSDP2 分片沿 dim-1 执行(非 FSDP2 默认的 dim-0)。规避「EP size × FSDP2 size 必须严格等于专家总数」的强限制,提升并行配置的灵活性。
通用化的专家模块识别:不依赖固定的命名规则(如 layer.mlp.experts)适配不同模型,而是复用模型定义中注册的 EP Plan 键值,自动推导专家模块,保证对不同 MoE 架构模型的兼容性。 非专家模块适配:非专家模块不受 EP 影响,仅执行原生 FSDP2 分片,分片大小等于全局 world size,仅使用 1 维的 FSDP 设备网格。
3. 定制化的预取配置(Configuring Proper Prefetching)
这是 EP+FSDP2 混合并行下的核心性能优化点,解决了原生配置的效率缺陷: - 原生配置的问题:EP+FSDP2 的嵌套分片结构,会导致 FSDP2 默认的预取配置效率极低。注意力模块和专家模块会被识别为独立层,注意力计算的耗时无法覆盖专家模块 AllGather 操作的通信耗时,无法实现有效的通信 - 计算重叠。 - VeOmni 的解决方案:手动定制预取逻辑,要求每个 Decoder 层在前向传播时预取下一个 Decoder 层的注意力和专家模块,在反向传播时预取上一个 Decoder 层的注意力和专家模块,最大化通信与计算的重叠度,显著提升训练吞吐量。

