什么是内存屏障(Memory Barrier)
内存屏障是一个CPU指令。它是这样一条指令:
- 确保一些特定操作执行的顺序;
- 影响一些数据的可见性(可能是某些指令执行后的结果)。
CPU核内部包含了多个执行单元。例如,现代Intel CPU包含了6个执行单元,可以组合进行算术运算,逻辑条件判断及内存操作。每个执行单元可以执行上述任务的某种组合。这些执行单元是并行执行的,这样指令也就是在并行执行。但如果站在另一个CPU角度看,这也就产生了程序顺序的另一种不确定性。即使在单线程环境下,代码执行顺序也不一定是编码时顺序,因为编译器和CPU可以在保证输出结果一样(在自己的线程中)的情况下对指令重排序,使性能得到优化。插入一个内存屏障,相当于告诉CPU和编译器先于这个命令的必须先执行,后于这个命令的必须后执行。
内存屏障另一个作用是强制更新一次不同CPU的缓存。例如,一个写屏障会把这个屏障前写入的数据刷新到缓存,这样任何试图读取该数据的线程将得到最新值,而不用考虑到底是被哪个cpu核心或者哪颗CPU执行的。
当一个程序执行时,只要最终的结果是一样的,指令是否被重排并不重要。例如,在一个循环里,如果循环体内没用到这个计数器,循环的计数器什么时候更新(在循环开始,中间还是最后)并不重要。编译器和CPU可以自由的重排指令以最佳的利用CPU,只要下一次循环前更新该计数器即可。并且在循环执行中,这个变量可能一直存在寄存器上,并没有被推到缓存或主存,这样这个变量对其他CPU来说一直都是不可见的。
如果一个变量由volatile修饰,Java内存模型将在对这个变量的写操作后插入一个写屏障指令(同步到共享内存),在读操作前插入一个读屏障指令。这意味着如果你对一个volatile变量进行写操作,你必须知道:1、一旦你完成写入,任何访问这个字段的线程将会得到最新的值。2、在你写入前,会保证所有之前发生的事已经发生,并且任何更新过的数据值也是可见的,因为内存屏障会把之前的写入值都刷新到缓存。
可见性
定义
可见性的定义常见于各种并发场景中,以多线程为例:当一个线程修改了线程共享变量的值,其它线程能够立即得知这个修改。
从性能角度考虑,没有必要在修改后就立即同步修改的值——如果多次修改后才使用,那么只需要最后一次同步即可,在这之前的同步都是性能浪费。因此,实际的可见性定义要弱一些,只需要保证:当一个线程修改了线程共享变量的值,其它线程在使用前,能够得到最新的修改值。
可见性可以认为是最弱的“
一致性”(弱一致),只保证用户见到的数据是一致的,但不保证任意时刻,存储的数据都是一致的(强一致)。下文会讨论“缓存可见性”问题,部分文章也会称为“缓存一致性”问题。
问题来源
一个最简单的可见性问题来自计算机内部的缓存架构:
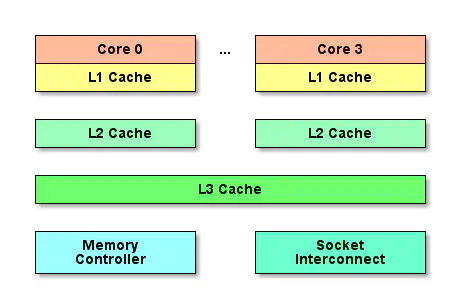
缓存大大缩小了高速CPU与低速内存之间的差距。以三层缓存架构为例:
- L1 Cache最接近CPU, 容量最小(如32K、64K等)、速度最高,每个核上都有一个L1 Cache。
- L2 Cache容量更大(如256K)、速度更低, 一般情况下,每个核上都有一个独立的L2 Cache。
- L3 Cache最接近内存,容量最大(如12MB),速度最低,在同一个CPU插槽之间的核共享一个L3 Cache。
准确地说,每个核上有两个L1 Cache, 一个存数据 L1d Cache, 一个存指令 L1i Cache。
单核时代的一切都是那么完美。然而,多核时代出现了可见性问题。一个badcase如下:
- Core0与Core1命中了内存中的同一个地址,那么各自的L1 Cache会缓存同一份数据的副本。
- 最开始,Core0与Core1都在友善的读取这份数据。
- 突然,Core0要使坏了,它修改了这份数据,使得两份缓存中的数据不同了,更确切的说,Core1
L1 Cache中的数据
失效了。
单核时代只有Core0,Core0修改Core0读,没什么问题;但是,现在_Core0修改后,Core1并不知道数据已经失效,继续傻傻的使用_,轻则数据计算错误,重则导致死循环、程序崩溃等。
实际的可见性问题还要扩展到两个方向:
- 除三级缓存外,各厂商实现的硬件架构中还存在多种多样的缓存,都存在类似的可见性问题。例如,寄存器就相当于CPU与L1 Cache之间的缓存。
- 各种高级语言(包括Java)的多线程内存模型中,在线程栈内自己维护一份缓存是常见的优化措施,但显然在CPU级别的缓存可见性问题面前,一切都失效了。
以上只是最简单的可见性问题,不涉及重排序等。
重排序也会导致可见性问题;同时,缓存上的可见性也会引起一些看似重排序导致的问题。
重排序
定义
重排序并没有严格的定义。整体上可以分为两种:
- 真·重排序:编译器、底层硬件(CPU等)出于“优化”的目的,按照某种规则将指令重新排序(尽管有时候看起来像乱序)。
- 伪·重排序:由于缓存同步顺序等问题,看起来指令被重排序了。
重排序也是单核时代非常优秀的优化手段,有足够多的措施保证其在单核下的正确性。在多核时代,如果工作线程之间不共享数据或仅共享不可变数据,重排序也是性能优化的利器。然而,如果工作线程之间共享了可变数据,由于两种重排序的结果都不是固定的,会导致工作线程似乎表现出了随机行为。
问题来源
重排序问题无时无刻不在发生,源自三种场景:
- 编译器编译时的优化
- 处理器执行时的乱序优化
- 缓存同步顺序(导致可见性问题)
场景1、2属于真·重排序;场景3属于伪·重排序。场景3也属于可见性问题,为保持连贯性,我们先讨论场景3。
可见性导致的伪·重排序
缓存同步顺序本质上是可见性问题。
假设程序顺序(program
order)中先更新变量v1、再更新变量v2,不考虑真·重排序:
- Core0先更新缓存中的v1,再更新缓存中的v2(位于两个缓存行,这样淘汰缓存行时不会一起写回内存)。
- Core0读取v1(假设使用LRU协议淘汰缓存)。
- Core0的缓存满,将最远使用的v2写回内存。
- Core1的缓存中本来存有v1,现在将v2加载入缓存。
重排序是针对程序顺序而言的,如果指令执行顺序与程序顺序不同,就说明这段指令被重排序了。
此时,尽管“更新v1”的事件早于“更新v2”发生,但Core1只看到了v2的最新值,却看不到v1的最新值。这属于可见性导致的伪·重排序:虽然没有实际上没有重排序,但看起来发生了重排序。
可以看到,缓存可见性不仅仅导致可见性问题,还会导致伪·重排序。因此,只要解决了缓存上的可见性问题,也就解决了伪·重排序。
内存屏障指令
同步的目的是保证不同执行流对共享数据并发操作的一致性。在单核时代,使用原子变量就很容易达成这一目的。甚至因为CPU的一些访存特性,对某些内存对齐数据的读或写也具有原子的特性。但在多核架构下即使操作是原子的,仍然会因为其他原因导致同步失效。
解决种种重排列和不可见问题的靠近硬件的解决方法是内存屏障,无论是Acquire/Release语义还是原子操作,亦或者是互斥锁,在底层实现均依赖于内存屏障指令。
#LoadLoad
该屏障之前的读不会乱序到该屏障之后,用版本管理系统类比的话相当于git pull。
1 | Load1; |
Load1 和 Load2 代表两条读取指令。在Load2要读取的数据被访问前,保证Load1要读取的数据被读取完毕。Load1读取到的值有可能不是最新的,这取决于其它线程的读写情况。但至少不会出现下面的情况:
1 | if (IsPublished) // Load and check shared flag |
有可能IsPublished还不为true(意味着其它线程对Value还没写好),就先读了旧的Value,如果没有LoadLOad屏障的话。
#StoreStore
该屏障之前的写不会乱序到该屏障之后,用版本管理系统类比的话相当于git push。
1 | Store1; |
Store1 和 Store2代表两条写入指令。在Store2写入执行前,保证Store1的写入操作对其它处理器可见,即强制更新一次不同CPU的缓存。例如:
1 | Value = x; // Publish some data |
如果其它线程看到IsPublished的值为1,那么数据一定已经写到共享内存中。
#LoadStore
1 | Load1; |
在Store2被写入前,保证Load1要读取的数据被读取完毕。
#StoreLoad
1 | Store1; |
在Load2读取操作执行前,保证Store1的写入对所有处理器可见。StoreLoad屏障的开销是四种屏障中最大的。
参考
- https://juejin.im/post/5a52cfdc518825733b0eb69a#heading-15

